
Beyond Moore's Law
Back in the 60’s, Intel co-founder Gordon Moore famously predicted that the number of transistors we can fit on a computer chip will double about every two years, with the implication that the speed of computers will grow just as fast. Although it was just an empirical observation at the time, it held true for the next several decades as computers went from slow behemoths to the ubiquitous, powerful devices they are today. However…
… Times are changing. Since about 2010, the performance of a “single” computer has hit a wall (see “Frequency” and “Single-Thread Performance” on Figure 1). There are many reasons for this: transistors are approaching the size of atoms, larger chips mean electrons have to travel farther, and higher clock speeds require more power, to name a few.
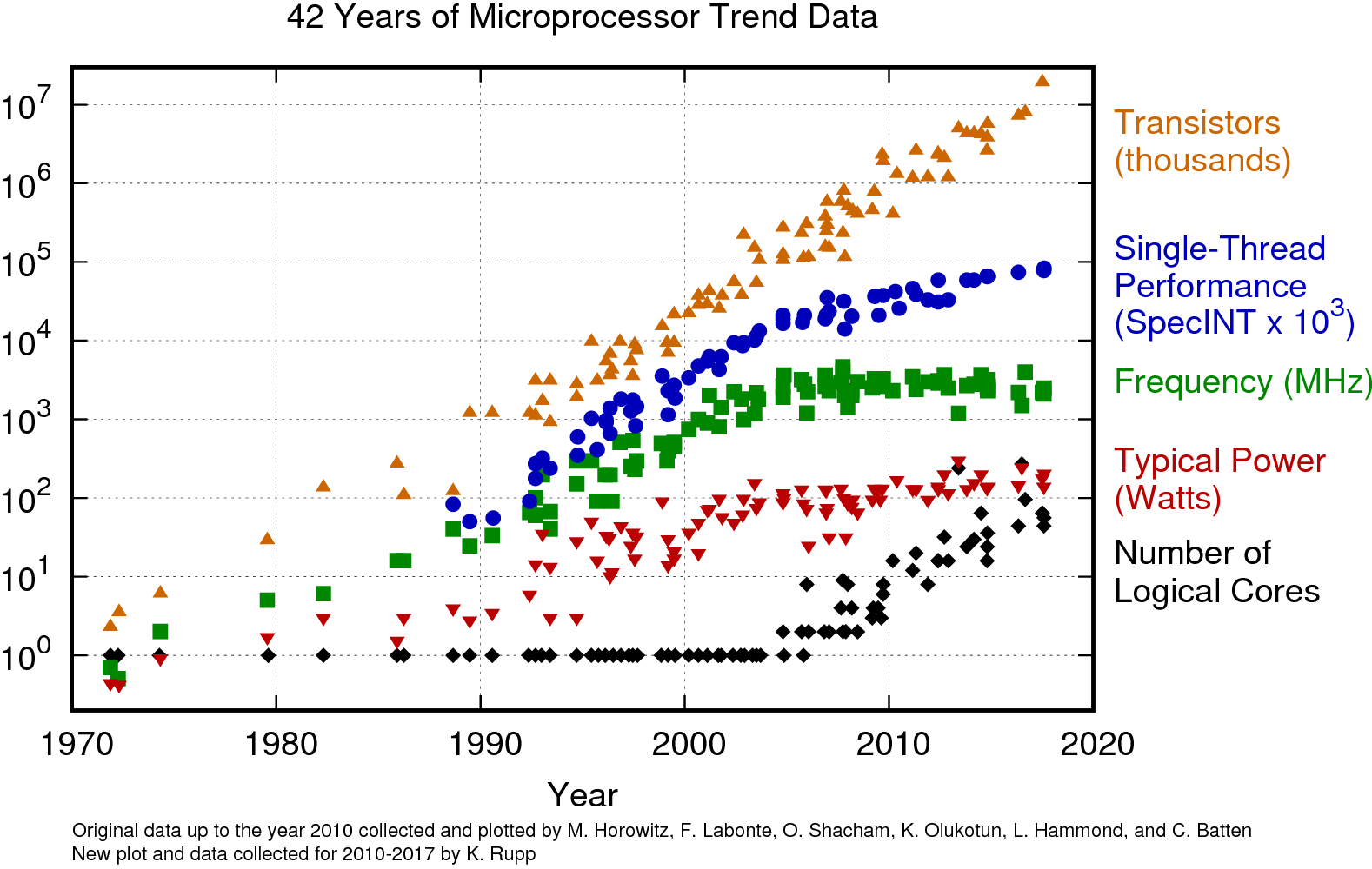 Figure 1: processor specs over the years
Figure 1: processor specs over the yearsAre we going to let silly little things like universal laws of physics stop us? Of course not. I’d like to talk about some newer ideas in computing that let us get around Moore’s Law. In fact, they’re already around us.
Table of Contents
Two Cores Are Better Than One
Even if you’re not sure what cores are, you’ve probably heard mentions of “dual-core” or “quad-core” processors (or more—good for you!) when you’re looking for a new computer. Reusing the cooking analogy from one of my previous posts, a core is like a single cook in the CPU “kitchen” that can follow one list of recipe instructions in order.
In a simpler time, processors such as the most of the Intel Pentium series have just one core. This means that at any given time, instructions from exactly one program are being run on the processor, and the illusion of many programs running on a computer at once is created by rapidly switching between different lists of instructions. With this model, speeding up a computer is simple in theory—make the processor do more instructions per second! More proper terms for this are clock speed or frequency. Problem is, we’ve already more or less pushed this method to its limit. If you look back at Figure 1, you’ll find that just comparing single core frequency, computers from over 10 years ago are already about as fast as ones from today.
Recently, we’ve been a lot more invested in increasing the number of cores per processor. Just like how having more hands in the kitchen lets us prepare multi-course meals faster, more cores means we’re better at handling multiple programs at once. We can’t run a single list of instructions any faster, but tons of things that we use computers for today can be split into separate, parallel tasks. A prime example is computer graphics; they are so embarassingly parallel that we have build a special type of processor for them, the GPU, with a lot more cores than standard CPUs, but each of them slower and less power-hungry.
So far we’ve been focusing on hardware, but parallel computing needs both software and hardware to work together. A programmer has many more things to consider when writing parallel code. For some intuition on this, imagine how multiple cooks in one kitchen need to communicate to make sure that they each have a defined role, that they’re not competing for ingredients or utensils, and that some step of a recipe is finished before another one that relies on it begins. Since multi-core processors have become prevalent in personal computers, parallel programs are now commonplace, and in many cases, essential.

Note: for simplicity, I’ve glossed over a lot of more technical concepts like logical vs. physical cores and parallelism vs. concurrency.
Farming Computers
Now we know that having multiple cores lets a computer get more work done. Can we apply this idea some other way? Not just multiple cores, but multiple computers?
That’s what many companies and institutions are doing today in so-called server farms or datacenters, only “multiple” is a hilarious understatement. Here’s what a small section of one looks like:
 View of a cooridor in a Google datacenter, lined with server racks
View of a cooridor in a Google datacenter, lined with server racksOn each rack of each shelf sits a computer. There’s probably a thousand computers in just this picture; a larger datacenter might have hundreds of thousands of networked computers, if not more! Even cooling all these computers is a herculean feat. To make the cost of such a thing even remotely reasonable, these computers are often fitted with easily replaceable commodity parts instead of high-end ones.
Nowadays, whenever you watch a YouTube video or post a funny tweet, your own computer is talking to a subset of server computers, a.k.a. nodes, in one of these distributed systems. This division of labor approach is the only way for huge online services to handle the obscene numbers of actions done by all of their users at any point in time. There are also many other critical applications such as big data, simulations, scientific computing, and machine learning. Much like the multi-core processors themselves, communication and coordination among many nodes is a challenge, but the scale is much larger, and designs can vary widely depending on specific scenarios.
Parallel and distributed computing go hand in hand, and they’re hot topics in industry as well as active areas of research. Many libaries like OpenMP and OpenMPI are being developed for this purpose, and some newer programming languages like Go put great emphasis on making parallel programs easier to write. One project started at UC Berkeley, Ray, has recently been gaining a lot of momentum. Also, shameless plug: I’m personally involved with the NumS project, which aims to bring the popular Python numerical library NumPy to distributed systems, and it currently uses Ray behind the scenes. There are countless people around the world who share the goals of boosting the power of parallel systems and making them accessible.
Living on the Edge
We’ve talked a lot about making computer systems more expansive and powerful, but now let’s go in the opposite direction for a moment and discuss edge computing.
Edge computing takes place close to us, the end users, in devices that many of us own or soon will like smartphones, self-driving cars, and home automation systems, but also in less visible places like localized servers. As AI tools and Internet-of-Things (IoT) devices become more and more deeply integrated in our lives, they each produce small streams of data that accumulate to massive lakes over time, and much of this data have to be processed somewhere. As powerful as centralized datacenters are, it still takes time to send data back and forth, and doing it too much can easily cause traffic jams on the highways for data. We can save tons of time by “going local” and only asking datacenters for help when we really need it.
In practice, edge computing can be considered as part of a distributed system that additionally tries to optimize for geographical closeness. Importantly, it uses the same principle of division of labor. With processors and data storage devices being as compact as they are now, it’s not too difficult to put extra computing power within our reach, but it still takes creativity to envision the many different configurations, and careful analysis to choose the best one.
An Exciting Time for Computers
When I first heard of Moore’s Law as a kid, it was explained to me as “Computers get twice as fast every two years!” At the time, kid me mistook this as some unchanging law of the universe, like Newton’s laws of motion and taxes. I thought it was humanity’s destiny to build exponentially faster computers, and so did many others. Ask a computer guy from 20 years ago about our knowledge of software and hardware design today, and they might say something like this—why optimize our programs and systems, when we can speed everything up just by buying next year’s shiny new chip?
But now, there’s no more computing power promised to us. We can no longer count on the guardian angels of chipmaking to bless us with perpetual increases in clock speed, and if we want to go any farther, it’s up to us to use our ingenuity and push our boundaries. The uncertainty of the path ahead may seem daunting, but this means we’re in an exciting time for computers.